How I Built a Large-Scale Analytics Pipeline for 200 TB of Solana On-Chain Data
Introduction
In late 2022 - early 2023, my startup needed to analyze 200 TB of Solana on-chain data to derive essential blockchain metrics such as Daily Active Users (DAU), Monthly Active Users (MAU), transaction volume, fees, and Total Value Locked (TVL). My data resided in AWS S3 in raw JSON format, and I needed a robust platform that would let me process these massive files efficiently. After considering various options, I chose Databricks on AWS.
In this post, I will walk through the challenges I faced, the system architecture I designed, how I implemented the solution in PySpark, and the results my team and I achieved.
Challenges and Requirements
- Data Volume: I had 200 TB of JSON files containing transactions, NFT trades, token transfers, and other Solana on-chain activity. Parsing such a huge volume of text data would be expensive and time-consuming.
- Complex Metrics: I wanted to capture not only transaction volumes and fees, but also more complex indicators like TVL, which required analyzing contracts and net flows into various protocols.
- Cost vs. Performance: My startup had AWS credits, but I still had to optimize the balance between cost and total processing time. I couldn't let the compute charges or S3 I/O costs spiral out of control.
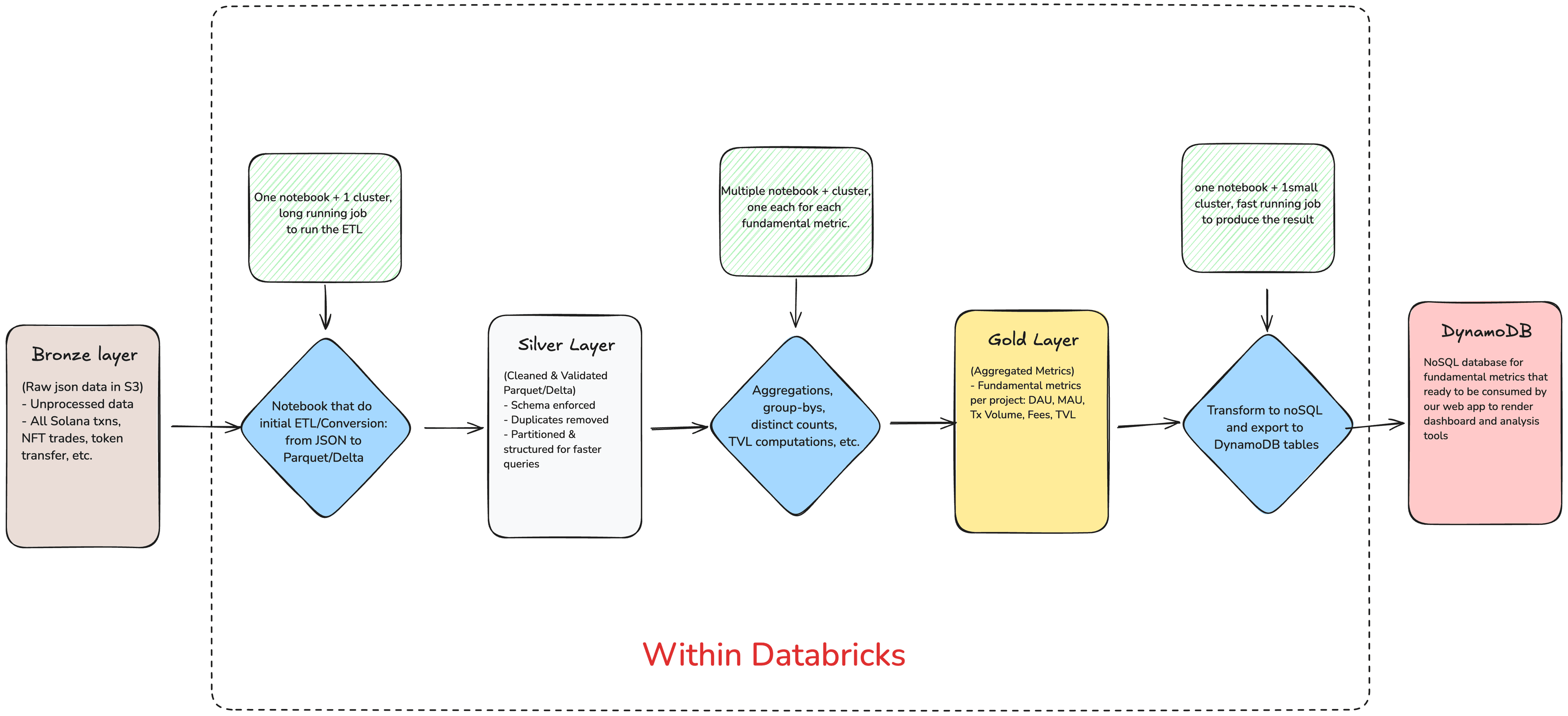
High-Level Architecture
- Data Source: All raw JSON data sat in AWS S3.
- Databricks Workspace: I used Databricks notebooks and jobs to develop and schedule my PySpark pipelines.
- Cluster Autoscaling: I configured an autoscaling Spark cluster (mostly using spot instances) to handle the heavy lifting of parsing and aggregations.
- ETL & Optimization: I converted JSON files to Parquet or Delta for more efficient columnar storage.
- Metric Computation: I performed group-bys and distinct counts to get DAU, MAU, fees, transaction volume, and a two-step calculation for TVL.
- Results & Visualization: I exported the results to DynamoDB to display in a dashboard and data analysis tools.
Here's a simplified diagram of the data processing pipeline:
Implementation Details
1. Parsing the JSON Data
My first step involved reading the raw JSON files from S3 using PySpark:
raw_df = spark.read.json("s3a://my-bucket/solana-raw/*.json")Because of the enormous file count and size, I explicitly defined the schema to avoid the overhead of schema inference. After validating the data layout, I used a schema that captured transaction IDs, addresses, timestamps, fees, and token amounts.
2. Converting JSON to Parquet
JSON is human-readable but quite verbose, so to optimize queries, I converted the raw DataFrame into Parquet:
transactions_df = raw_df.select(
"timestamp",
"user_address",
"counterparty_address",
"tx_value",
"fee"
# ...
)Cluster and Compute Setup
- Instance Choice: I settled on i3.2xlarge (and sometimes r5.4xlarge) for memory and I/O throughput. My cluster typically started with 20 workers and could autoscale up to 100.
- Autoscaling & Spot Instances: I enabled autoscaling to handle big shuffles without over-provisioning. I also used spot instances to reduce EC2 costs by up to 70%. Whenever a spot node was reclaimed, Spark automatically retried the tasks on another node.
- Shuffle and Partition Tuning: I increased spark.sql.shuffle.partitions to a few thousand for distributing the load of distinct counts and group-bys. Adaptive Query Execution (AQE) in Spark 3 helped handle data skew automatically.
Cost and Time Results
- Data Conversion Stage: Converting 200 TB of JSON to Parquet took around 24 hours on average with about 25 worker nodes. This single pass saved me from re-parsing JSON in future analyses.
- Metric Computations: After I had the data in Parquet, daily or monthly metrics ran significantly faster—often within a few hours.
- S3 I/O Costs: Reading 200 TB was the biggest factor, but using Parquet instead of raw JSON cut down repeated scans.
Lessons Learned
- Columnar Storage: Converting to Parquet significantly improved performance and slashed storage sizes.
- Autoscaling Strategy: Letting the cluster scale up during heavy reads, then scale down automatically, struck a good balance between speed and cost.
- Handling Skew: Big group-bys can create outlier tasks if certain days have disproportionately more transactions. Increasing spark.sql.shuffle.partitions and enabling AQE helped mitigate that.
- TVL Complexity: I realized that computing TVL accurately often involves domain knowledge of each DeFi protocol. I had to do extra research on which addresses qualified.
- Resilience: Breaking the pipeline into distinct stages (ETL, metric calculation, final aggregation) allowed me to resume partway if anything failed.