Building an MLOps Pipeline for Our AI-Powered Game Creation App
At my startup, we've been developing a mobile app that lets users create their own video games using AI-generated text, images, and sound—no coding required. Over the past few months, I worked on implementing a robust MLOps pipeline to improve the quality of prompts that power our LLM-based content creation. Here's how we tackled it and the lessons I learned along the way.
Background: Why We Needed MLOps
When we first launched, our daily active users (DAU) hovered around 1,000, and we noticed two key challenges with our existing system:
- Prompt Quality: As we introduced new templates for our AI models, it became clear we needed a systematic way to test, monitor, and optimize these prompts to ensure we consistently delivered high-quality text, images, and sounds to users.
- Continuous Iteration: We realized that "set it and forget it" wasn't going to work for our LLM-driven app. The only way to keep improving was to gather real-world usage data and user feedback, then feed that back into our prompt engineering process.
The Stack
Based on our product requirements and existing infrastructure, I built an MLOps pipeline using:
- Humanloop for prompt monitoring and logging.
- Promptfoo for systematic prompt evaluation and A/B testing.
- DSPy for automated prompt optimization.
- AWS DynamoDB as our main storage for prompt logs and user interactions.
- A CI/CD pipeline that integrated with our source control to automatically deploy new prompt updates once they passed our tests.
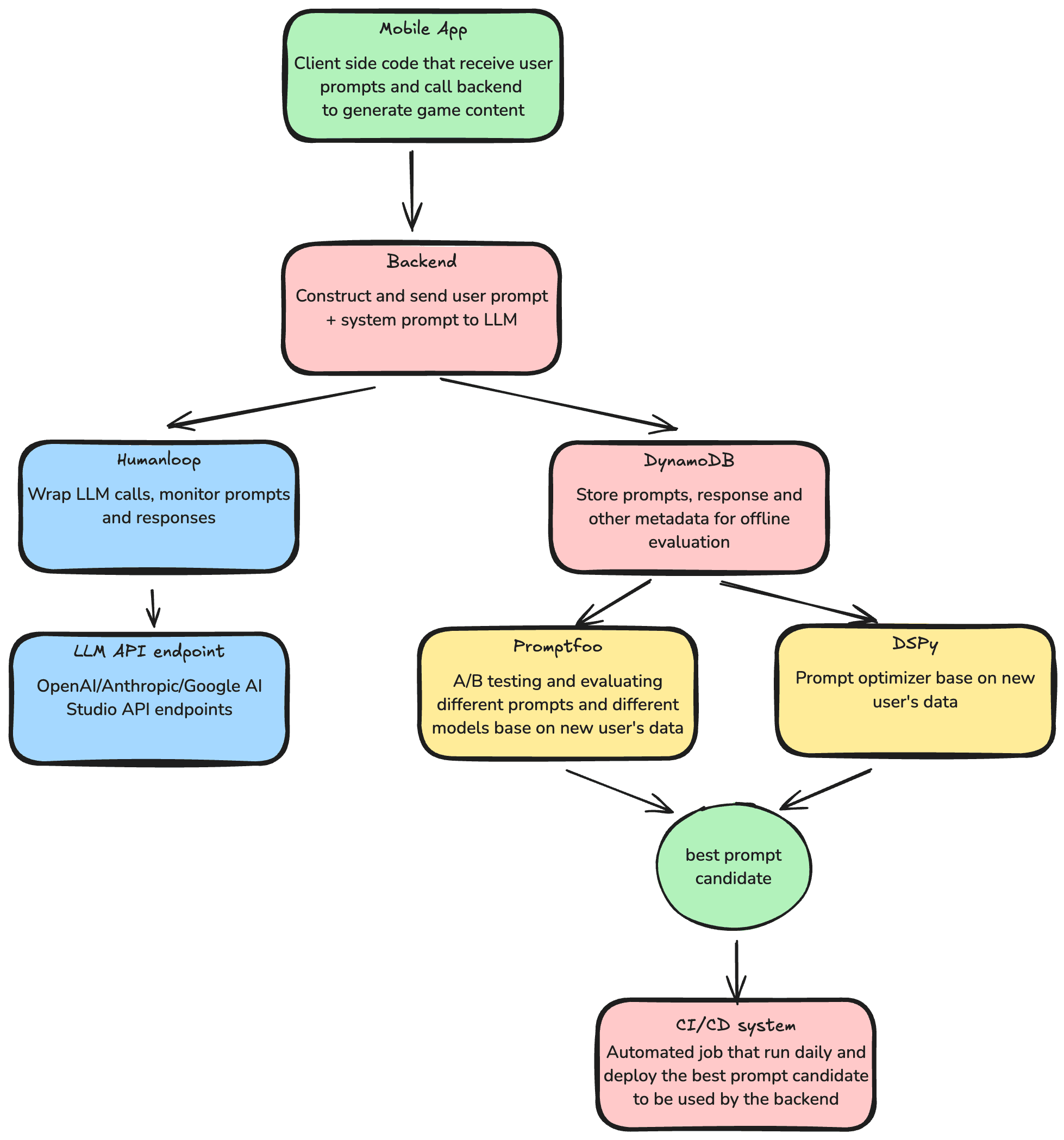
Architecture Overview
I designed our architecture to route user interactions and AI-generated outputs into a data pipeline that gave us immediate visibility into performance and enabled nightly or weekly prompt updates. Here's a high-level summary:
- Mobile App (Frontend): Users typed in their game ideas and chose settings like genre or style. The frontend sent these inputs to our backend API.
- Backend API: On the backend, I used the latest approved prompt template to construct a prompt for the large language model. We also called specialized image and audio generation services for rich media content.
- Humanloop: Each prompt and its response was logged through Humanloop, letting us track and monitor LLM performance in a centralized dashboard.
- AWS DynamoDB: We wrote prompt interactions (including outputs and metadata) to DynamoDB for long-term storage and analytics.
- Promptfoo & DSPy (Offline): Periodically, we ran offline evaluations. Promptfoo tested how different prompt templates (and sometimes different models) performed on curated input sets, while DSPy automatically refined our prompts based on user feedback and scoring.
- CI/CD Pipeline: Once we found a better-performing prompt version, we committed it to our repository. Our CI pipeline ran Promptfoo tests to verify prompt quality. If it passed, the pipeline automatically deployed the new prompt to production.
Here's our MLOps pipeline architecture:
Implementation Details
1. Logging and Monitoring with Humanloop
I first connected our backend to Humanloop, which offered an SDK to log every LLM call. This meant every time a user created or updated a game concept, the system prompt and the resulting AI-generated content were recorded in Humanloop's dashboards. We could see, in near real-time, the rate of successful generations versus errors, plus how often users retried a generation.
In practice, I replaced direct calls to the LLM API with a wrapper function that included a call to Humanloop's logging method. I also stored the raw user input, the final prompt, and relevant metadata in DynamoDB. This gave me a single source of truth for deeper analysis.
2. Offline Evaluation with Promptfoo
Next, I integrated Promptfoo to run automated prompt tests and A/B comparisons. I created a YAML configuration file listing sample user inputs and the expected or desired elements in the outputs. Promptfoo allowed me to compare:
- Prompt A: The current production prompt.
- Prompt B: A new variant with updated instructions or examples.
Promptfoo returned a pass/fail score for each test case. If Prompt B consistently outperformed Prompt A, it became a candidate for production. I also introduced some advanced checks—like verifying whether the text output contained critical keywords (e.g., "dragon," "puzzle," "space exploration") when users requested specific themes.
3. Automated Prompt Optimization with DSPy
We wanted to reduce the trial-and-error time it took to craft better prompts, so I used DSPy to automate part of the optimization. I compiled a small dataset of real user inputs and any labeled "best" outputs from DynamoDB. Then I configured DSPy with a scoring function that reflected user satisfaction—namely, whether the generated text included all requested elements and followed a logical storyline.
DSPy iteratively tweaked the system prompt. After each small adjustment, it compared the new prompt's performance (based on the scoring function) to the old baseline. Over multiple iterations, DSPy sometimes found prompt variations that performed better than those I had manually crafted.
4. DynamoDB Data Flow
The final piece was ensuring all prompt interactions were safely stored in DynamoDB. This table included the user ID, prompt version, prompt text, model type, timestamps, and user feedback (if any). Because of DynamoDB's on-demand capacity mode, we didn't have to worry about throughput provisioning or scaling—an important factor as our user base started to grow.
5. CI/CD for Prompt Deployment
To avoid manual merges every time we discovered a better prompt, I set up a CI/CD pipeline using GitHub Actions. My pipeline did the following:
- Pull Request: I updated a configuration file containing the prompt text whenever I had a new version.
- Run Promptfoo Tests: GitHub Actions spun up a test environment and ran the Promptfoo suite. If the new prompt failed any tests, the pipeline blocked the merge.
- Deploy on Success: If the new prompt passed all checks, the pipeline automatically built and deployed our backend service with the updated prompt version.
- Humanloop Logging: As soon as the new prompt went live, we could confirm in Humanloop's dashboard that users were now being served the newly deployed prompt.
Results and Lessons Learned
- Reduced Guesswork: Having a data-driven pipeline significantly cut down on guesswork. Instead of spending hours or days manually iterating on prompts, we leveraged real metrics from Promptfoo and DSPy to find optimal formulations.
- Easier Rollbacks: Because everything was version-controlled, rolling back to a previous prompt was trivial. If a new prompt performed worse than expected, we just reverted the commit and redeployed.
- Continuous Improvement: By scheduling weekly offline evaluations, we systematically gathered fresh data from DynamoDB. This made each iteration more representative of real users' needs, thus improving prompt performance over time.
- Scalability: Since we relied on AWS DynamoDB, we didn't encounter performance bottlenecks as our DAU continued to climb. Meanwhile, Humanloop handled the increased log volume without any problems.